
机器学习系列是我学习 CS 189/289A Introduction to Machine Learning Spring 2025 时记录的学习笔记,也可以当作是对课程笔记的翻译,经供参考。
分类问题
- 收集具有标签的训练样本
- 预测新样本的类别
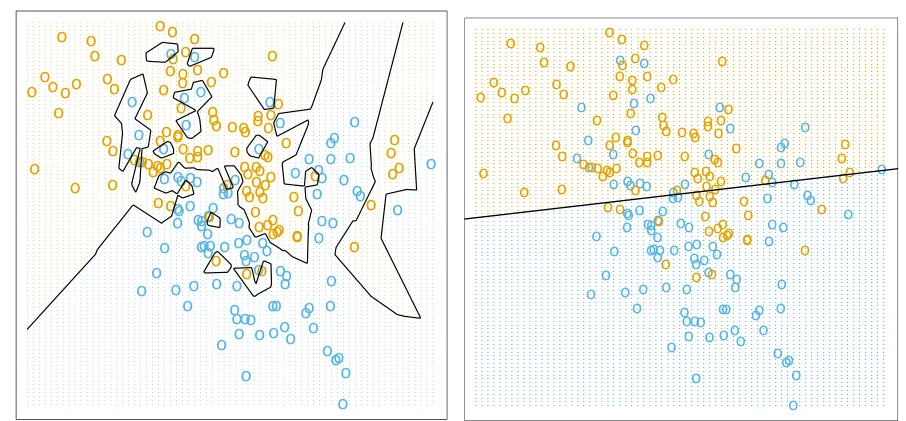
两种不同分类器的决策边界
训练、验证和测试
- 我们拥有一些设置好标签的数据
- 从数据中取出一部分作为验证集(通常 20),其余作为训练集
- 训练一个或者多个分类器:训练多种不同算法,或者具有不同超参数的同一算法
- 使用验证集选出具有最低验证误差的分类器
- 使用新的数据测试算法的效果
训练误差:训练集中分类错误的比例
验证误差:验证集中分类错误的比例
测试误差:测试集中分类错误的比例
大多数机器学习算法的一些超参数改变会造成欠拟合或者过拟合
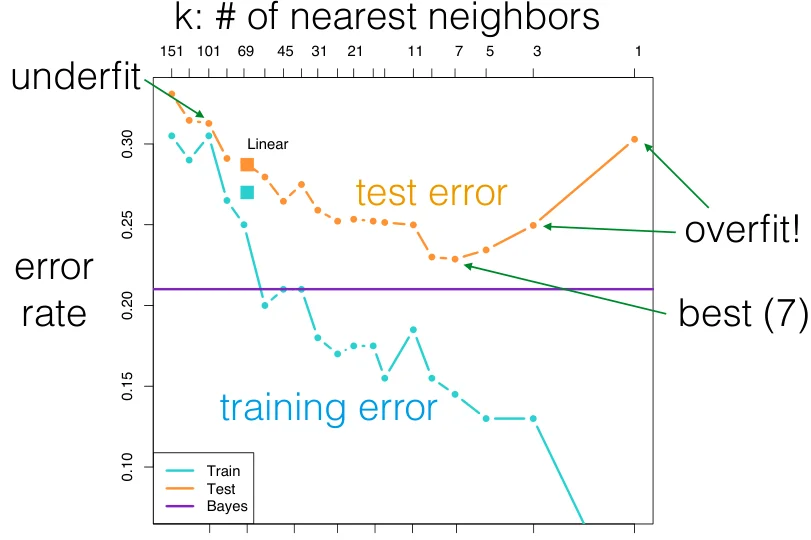
[k邻接算法中超参数k的改变带来的影响]
- 过拟合:当验证/测试误差恶化时,原因是分类器对异常值或其他虚假模式变得过于敏感。
- 欠拟合:当验证/测试误差恶化时,原因是分类器不够灵活,无法拟合模式。
- 异常值:具有非典型标签的点(例如,富裕的借款人仍然违约)。增加过拟合的风险。